Version Control#
Why use version control?#
When we develop code, we are going to be making lots of changes over time. And you will find yourself in the following situations:
You swear that the code worked perfectly 6 months ago but today it doesn’t and you can’t figure out what changed.
The code looks different than you remembered and you don’t know why it changed.
Your research group is all working on the same code and you need to sync up with everyone’s changes and make sure that no one breaks the code.
This is what version control does for us.
Note
Version control systems keep track of the history of changes to source code and allow multiple developers to all work on the same code base.
In particular:
Logs tell you what changes have been made to each file over time.
You can request the source as it was at any time in the past.
Multiple developers can all work on the same source code and share and synchronize changes.
Changes by different developers to the same file are merged.
If two developers changed the same part of a file, version control provides mechanisms to resolve conflicts.
You can make a branch and work on new features without breaking the current working code, and when you are ready, merge those changes into the main version.
Note
Even for a single developer, version control is a great asset.
Common task: you notice your code is giving different answers than you’ve seen in the past.
With version control, you can checkout an old copy when you know it was working, and ask for the difference with the current code.
Tip
Version control is not just for source code. You can use it for writing papers in LaTeX, course notes, etc.
Centralized vs. distributed version control#
Broadly speaking, there are two different types of version control: centralized and distributed. We’ll call the collection of code under version control the repository.
Centralized version control#
Examples: CVS, subversion
A server holds the master copy of the source, stores the history, changes
Each user communicates with the server:
“checkout” source
“commit” changes back to the source
request the log (history) of a file from the server
“diff” your local version with the version on the server
This is the older style of version control, and not widely used for new projects.
Distributed version control#
Examples: git, mercurial
Everyone has a full-fledged repository
Commits, history, diff, logs, etc. are all local operations
You can clone another person’s repo and they can pull your changes back to their version
Each copy is a backup of the whole history of the project
Easy to “fork”—just clone and go.
Tip
Any version control system is better than no version control.
Git is the most popular right now, so we’ll focus on that.
Consider the figure below:
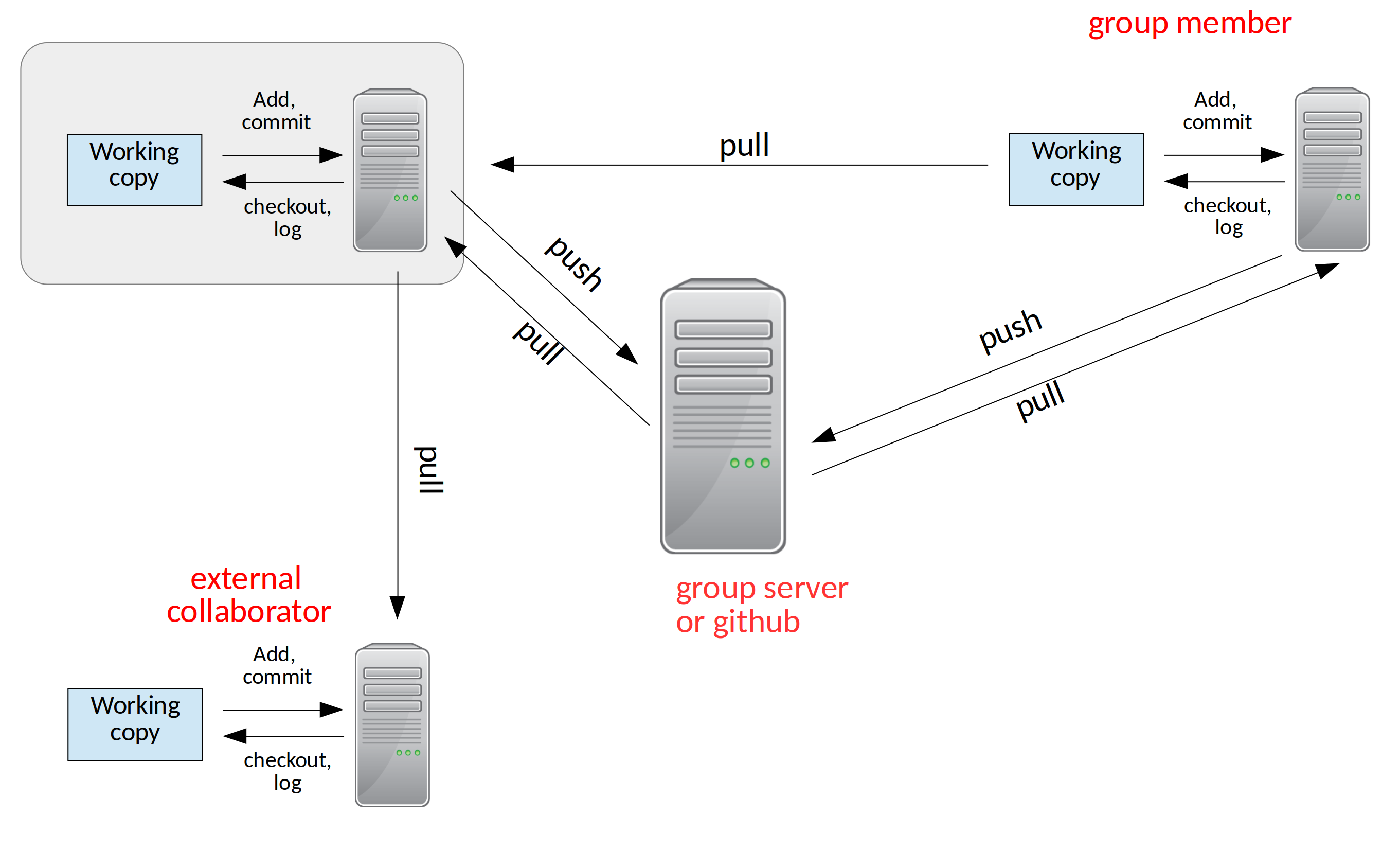
We see:
You in the upper left box interacting with your local computer. You can add changes to your repo and query the log, etc. all just using your own machine.
Your colleague in the upper right. They can also interact with their own computer, using their own version of the repo.
Now, imagine that they make a change that you want. You can pull their version of the code into your repo, getting all of their changes.
Suppose you both want to efficiently share work as a group. So you setup a group server and you can both synchronize your repo with that server by doing pull and push.
This server provides a mechanism for everyone in the group to stay in sync.
Imagine now that you have an external collaborator who doesn’t have access to your server. You can let them pull from your copy of the repo, without giving them permission to push changes back.
They can then interact with their copy locally.