OpenMP#
OpenMP provides a directive-based approach to marking regions of code for parallelism. It supports shared-memory parallelism and offloading to accelerators.
Some nice examples are provided in the OpenMP Application Programming Interface Examples document.
Tip
The OpenMP Reference Guide provides a quick overview of the different syntax in OpenMP.
Compiler support#
In order to build an OpenMP application, you need a compiler that supports it. Fortunately, most recent compilers support OpenMP. For g++, the OpenMP standards are fully supported (up to version 5.0)
See this table for compiler support for OpenMP.
Threads#
In an OpenMP application, threads are spawned as needed.
When you start the program, there is one thread—the master thread
When you enter a parallel region, multiple threads run concurrently
This looks like:
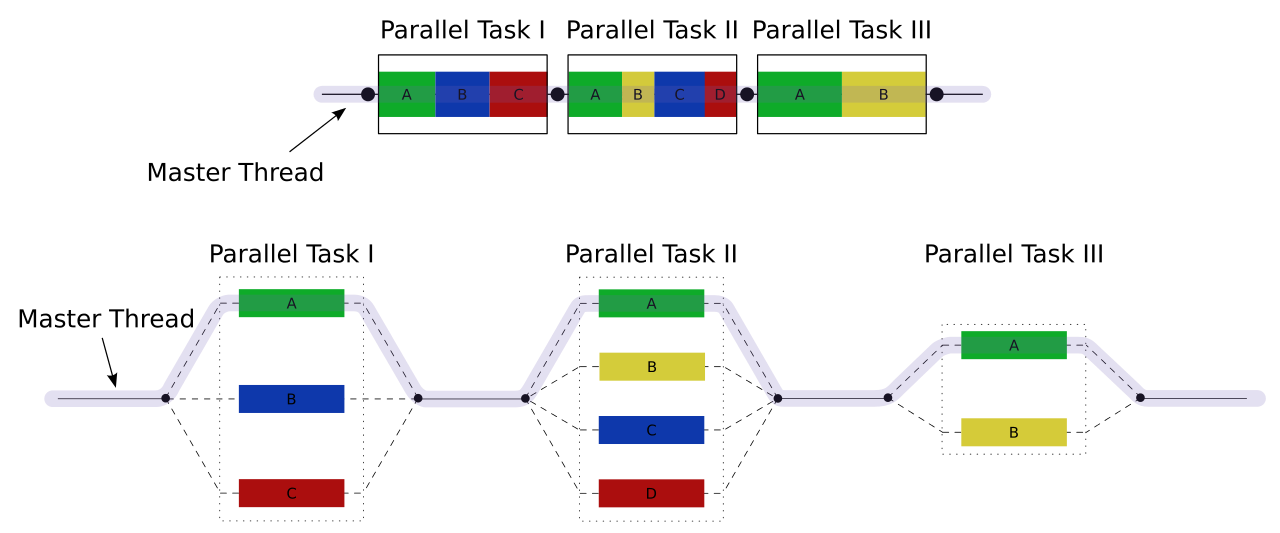
Fig. 19 (A1 / Wikipedia)#
Hello, World#
Here’s a simple “Hello, World” in OpenMP. We print out the number of threads and then enter a parallel region where each thread prints its id separately:
#include <iostream>
#include <omp.h>
int main() {
std::cout << "total number of threads = " << omp_get_max_threads() << std::endl;
#pragma omp parallel
{
std::cout << "Hello from thread " << omp_get_thread_num() << std::endl;
}
}
When we compile this, we need to tell the compiler to interpret the OpenMP directives:
g++ -fopenmp -o hello hello.cpp
A few notes:
OpenMP directives are specified via
#pragma ompWhen we run this, the threads are all printing independent of one another, so the output is all mixed up. Run it again and you’ll see a different ordering.
There are a few library functions that we access, by including
omp.h
Critical regions#
We can use a critical region in an OpenMP parallel region to force
the threads to operate one at a time. For example, in the above
hello.cpp, we can get the prints to be done one at a time as:
#include <iostream>
#include <omp.h>
int main() {
std::cout << "total number of threads = " << omp_get_max_threads() << std::endl;
#pragma omp parallel
{
#pragma omp critical
std::cout << "Hello from thread " << omp_get_thread_num() << std::endl;
}
}
Controlling the number of threads#
The easiest way to control the number of threads an OpenMP application
uses is to set the OMP_NUM_THREADS environment variable. For
instance, you can set it globally in your shell as:
export OMP_NUM_THREADS=2
or just for the instance of your application as:
OMP_NUM_THREADS=2 ./hello
Tip
Your code will still run if you specify more threads than there are cores in your machine. On a Linux machine, you can do:
cat /proc/cpuinfo
To see the information about your processor and how many cores Linux thinks you have.
Note: modern processors sometimes use hyperthreading, which makes a single core look like 2 to the OS. But OpenMP may not benefit from this hardware threading.
Parallelizing Loops#
Here’s a matrix-vector multiply:
#include <iostream>
#include <omp.h>
#include <vector>
// be careful about memory (N**2)
// N = 10000 is 0.75 GB of memory
const int N = 10000;
int main() {
auto start = omp_get_wtime();
std::vector<std::vector<double>> a(N, std::vector<double>(N, 0));
std::vector<double> x(N, 0);
std::vector<double> b(N, 0);
#pragma omp parallel
{
#pragma omp for
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
a[i][j] = static_cast<double>(i + j);
}
x[i] = static_cast<double>(i);
b[i] = 0.0;
}
#pragma omp for
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
b[i] += a[i][j] * x[j];
}
}
}
auto end = omp_get_wtime();
std::cout << "execution time (s) = " << end - start << std::endl;
}
Warning
There is an overhead associated with spawning threads, and some regions might not have enough work to offset that overhead. Some experimentation may be necessary with your application.
Tip
We cannot put the { on the same line as the #pragma, since the
#pragma is dealt with by the preprocessor. So we do:
#pragma omp parallel
{
...
}
and not
#pragma omp parallel {
...
}
One thing we want is for the performance to scale with the number of cores—if you double the number of cores, does the code run twice as fast?
Reductions#
Reductions (e.g., summing, min/max) are trickier, since each thread will be updating its local sum or min/max, but then at the end of the parallel region, a reduction over the threads needs to be done.
A reduction clause takes the form:
#openmp parallel reduction (operator | variable)
Each thread will have its own local copy of variable and they will
be reduced into a single quantity at the end of the parallel region.
The possible operators are listed here: https://www.openmp.org/spec-html/5.0/openmpsu107.html and include:
+for summation-for subtraction*for multiplicationminfor finding the global minimummaxfor finding the global maximum
Here’s an example where we construct the sum:
Note
This will give slightly different answers depending on the number of threads because of different roundoff behavior.
#include <iostream>
#include <iomanip>
#include <cmath>
#include <omp.h>
int main() {
auto start = omp_get_wtime();
double sum{0.0};
#pragma omp parallel reduction(+:sum)
{
#pragma omp for
for (int i = 0; i < 10000; ++i) {
sum += std::exp(static_cast<double>(i % 5) -
2.0 * static_cast<double>(i % 7));
}
}
auto end = omp_get_wtime();
std::cout << std::setprecision(15) << sum << std::endl;
std::cout << "execution time (s) = " << end - start << std::endl;
}