Floating Point#
Storage overview#
We can think of a floating point number as having the form:
Most computers follow the IEEE 754 standard for floating point, and we commonly work with 32-bit and 64-bit floating point numbers (single and double precision). These bits are split between the signifcand and exponent as well as a single bit for the sign:
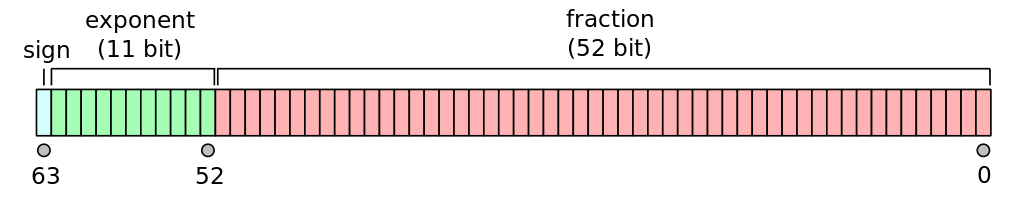
Fig. 12 (source: wikipedia)#
Since the number is stored in binary, we can think about expanding a number in powers of 2:
In fact, 0.1 cannot be exactly represented in floating point:
#include <iostream>
#include <iomanip>
int main() {
double a = 0.1;
std::cout << std::setprecision(19) << a << std::endl;
}
Precision#
With 52 bits for the significand, the smallest number compared to 1 we can represent is
but the IEEE 754 format always expresses the significant such that the
first bit is 1 (by adjusting the exponent) and then doesn’t need
to store that 1, giving us an extra bit of precision, so the
machine epsilon is
We already saw how to access the limits of the data type via
std::numeric_limits. When we looked at machine epsilon, we saw that for a
double it was about \(1.1\times 10^{-16}`\).
Note that this is a relative error, so for a number like 1000 we could only add
1.1e-13 to it before it became indistinguishable from 1000.
Note that there are varying definitions of machine epsilon which differ by a factor of 2.
Range#
Now consider the exponent, we use 11 bits to store it in double precision. Two are reserved for special numbers, so out of the 2048 possible exponent values, one is 0, and 2 are reserved, leaving 2045 to split between positive and negative exponents. These are set as:
converting to base 10, this is
Reporting values#
We can use std::numeric_limits<double> to query these floating point properties:
#include <iostream>
#include <limits>
int main() {
std::cout << "maximum double = " << std::numeric_limits<float>::max() << std::endl;
std::cout << "maximum double base-10 exponent = " << std::numeric_limits<float>::max_exponent10 << std::endl;
std::cout << "smallest (abs) double = " << std::numeric_limits<float>::min() << std::endl;
std::cout << "minimum double base-10 exponent = " << std::numeric_limits<float>::min_exponent10 << std::endl;
std::cout << "machine epsilon (double) = " << std::numeric_limits<float>::epsilon() << std::endl;
}
Roundoff vs. truncation error#
Consider the Taylor expansion of \(f(x)\) about some point \(x_0\):
where \(\Delta x = x - x_0\)
We can solve for the derivative to find an approximation for the first derivative:
This shows that this approximation for the derivative is first-order accurate in \(\Delta x\)—that is the truncation error of the approximation.
We can see the relative size of roundoff and truncation error by using this approximation to compute a derivative for different values of \(\Delta x\):
#include <iostream>
#include <iomanip>
#include <cmath>
#include <limits>
#include <vector>
double f(double x) {
return std::sin(x);
}
double dfdx_true(double x) {
return std::cos(x);
}
struct point {
double dx;
double err;
};
int main() {
double dx = 0.1;
double x0 = 1.0;
std::vector<point> data;
while (dx > std::numeric_limits<double>::epsilon()) {
point p;
p.dx = dx;
double dfdx_approx = (f(x0 + dx) - f(x0)) / dx;
double err = std::abs(dfdx_approx - dfdx_true(x0));
p.err = err;
data.push_back(p);
dx /= 2.0;
}
std::cout << std::setprecision(8) << std::scientific;
for (auto p : data) {
std::cout << std::setw(10) << p.dx << std::setw(15) << p.err << std::endl;
}
}
It is easier to see the behavior if we make a plot of the output:
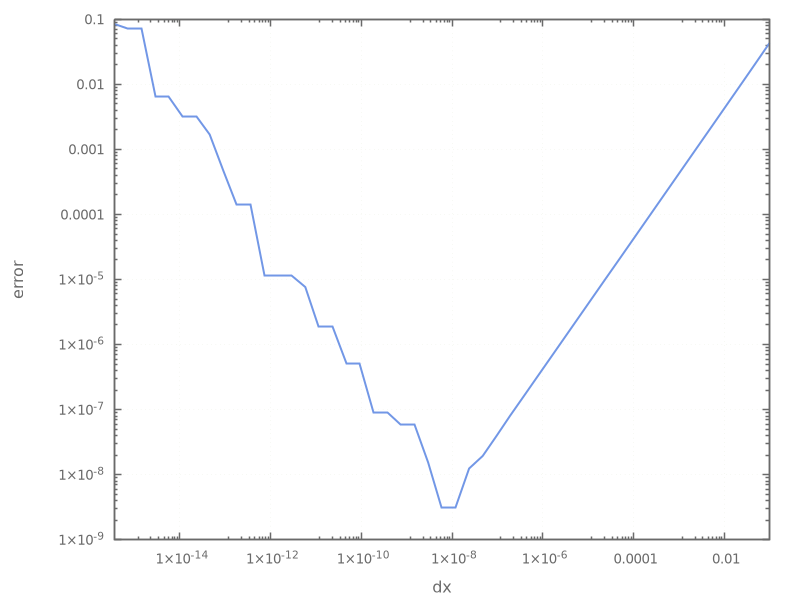
Let’s discuss the trends:
Starting with the largest value of \(\Delta x\), as we make \(\Delta x\) smaller, we see that the error decreases. This is following the expected behavior of the truncation error derived above.
Once our \(\Delta x\) becomes really small, roundoff error starts to dominate. In effect, we are seeing that:
\[(x_0 + \Delta x) - x_0 \ne 0\]because of roundoff error.
The minimum error here is around \(\sqrt{\epsilon}\), where \(\epsilon\) is machine epsilon.
Testing for equality#
Because of roundoff error, we should never exactly compare two floating point numbers, but instead ask they they agree within some tolerance, e.g., test equality as:
For example:
#include <iostream>
int main() {
double h{0.01};
double sum{0.0};
for (int n = 0; n < 100; ++n) {
sum += h;
}
std::cout << "sum == 1: " << (sum == 1.0) << std::endl;
std::cout << "|sum - 1| < tol: " << (std::abs(sum - 1.0) < 1.e-10) << std::endl;
}
Minimizing roundoff#
Consider subtracting the square of two numbers—taking the difference of two very close-in-value numbers is a prime place where roundoff can come into play.
Instead of doing:
we can instead do:
by factoring this, we are subtracting more reasonably sized numbers, reducing the roundoff.
We can see this directly by doing this with single precision (float) and comparing to an answer computed via double precious (double)
Here’s an example:
#include <iostream>
int main() {
float x{1.00001e15};
float y{1.0000e15};
std::cout << "x^2 - y^2 : " << x*x - y*y << std::endl;
std::cout << "(x - y)(x + y) : " << (x - y) * (x + y) << std::endl;
double m{1.000001e15};
double n{1.0000e15};
std::cout << "double precision value: " << (m - n) * (m + n) << std::endl;
}
As another example, consider computing [1]:
We can alternately rewrite this to avoid the subtraction of two close numbers:
Again we’ll compare a single-precision calculation using each of these methods
to a double precision “correct answer”. To ensure that we use the
single-precision version of the std::sqrt() function, we will use single
precision literal suffix, e.g., 1.0f tells the compiler that this is a
single-precision constant.
#include <iostream>
#include <iomanip>
#include <cmath>
int main() {
float x{201010.0f};
std::cout << std::setprecision(10);
float r1 = std::sqrt(x + 1.0f) - std::sqrt(x);
float r2 = 1.0f / (std::sqrt(x + 1.0f) + std::sqrt(x));
std::cout << "r1 = " << r1 << " r2 = " << r2 << std::endl;
double xd{201010.0};
double d = std::sqrt(xd + 1.0) - std::sqrt(xd);
std::cout << "d = " << d << std::endl;
}
Notice that we get several more significant digits correct when we compute it with the second formulation compared to the original form.
Summation algorithms#
Summing a sequence of numbers is a common place where roundoff error comes into play, especially if the numbers all vary in magnitude and you do not attempt to add them in a sorted fashion. There are a number of different summation algorithms that keep track of the loss due to roundoff and compensate the sum, for example the Kahan summation algorithm.
Special numbers#
IEEE 754 defines a few special quantities:
NaN(not a number) is the result of0.0/0.0orstd::sqrt(-1.0)Inf(infinity) is the result of1.0/0.0-0is a valid number and the standard says that-0is equivalent to0