MPI Send and Receive#
The main concept in MPI is sending messages between processes. Two
basic functions: MPI_Send() and MPI_Recv() provide this
functionality. You provide a buffer that contains the data you want
to send / receive.
MPI_Send()andMPI_Recv()are a blocking send/receive.For the sending code, the program resumes when it is safe to reuse the buffer.
For the receiving code, the program resumes when the message was received.
This may cause network contention if the destination process is busy doing its own communication. There are non-blocking sends that we can use in this case.
Here’s the interface for MPI_Send(): https://www.mpich.org/static/docs/v3.0.x/www3/MPI_Send.html
Here’s the interface for MPI_Recv(): https://www.mpich.org/static/docs/v3.0.x/www3/MPI_Recv.html
Basic example#
Here’s a basic example that mimics the ghost cell filling process used in hydrodynamics codes or in the relaxation problem.
On each processor we allocate an integer vector of 5 elements
We fill the middle 3 element with a sequence based on the processor number. Processor 0 gets
0, 1, 2, processor 1 gets3, 4, 5, and so on.We send messages to the left and right element with the corresponding element from the neighboring processors.
This looks like:
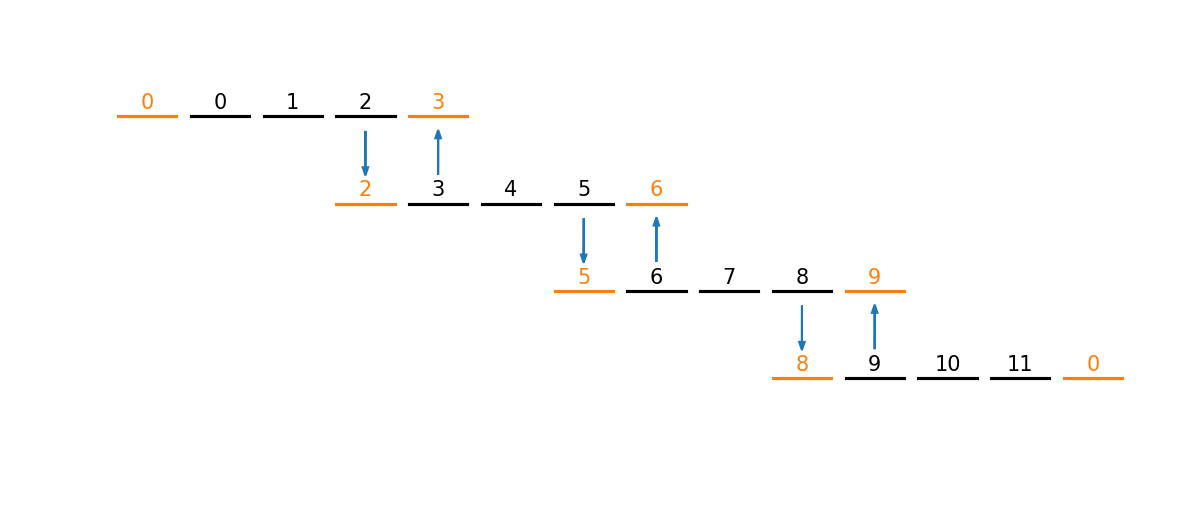
Fig. 20 Sharing data at the boundary of our vectors#
Here’s the implementation:
#include <iostream>
#include <vector>
#include <mpi.h>
int main() {
MPI_Init(nullptr, nullptr);
std::vector<int> data(5, 0);
int mype{-1};
MPI_Comm_rank(MPI_COMM_WORLD, &mype);
int num_procs{0};
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
// fill the interior 3 data elements
data[1] = 3 * mype;
data[2] = 3 * mype + 1;
data[3] = 3 * mype + 2;
// send to the left
if (mype > 0) {
MPI_Send(&data[1], 1, MPI_INT, mype-1, mype, MPI_COMM_WORLD);
}
MPI_Status status;
if (mype < num_procs-1) {
MPI_Recv(&data[4], 1, MPI_INT, mype+1, mype+1, MPI_COMM_WORLD, &status);
}
// send to the right
if (mype < num_procs-1) {
MPI_Send(&data[3], 1, MPI_INT, mype+1, mype, MPI_COMM_WORLD);
}
if (mype > 0) {
MPI_Recv(&data[0], 1, MPI_INT, mype-1, mype-1, MPI_COMM_WORLD, &status);
}
std::cout << "PE: " << mype << " data: ";
for (int i = 0; i < data.size(); ++i) {
std::cout << data[i] << " ";
}
std::cout << std::endl;
MPI_Finalize();
}
Notice that at the two ends, we don’t send anything in one case (for processor 0, there is no left, and for processor \(N-1\), there is no right).
MPI_Sendrecv#
Good communication performance often requires staggering the
communication. A combined MPI_Sendrecv can help with this. We
can use MPI_PROC_NULL when there is no destination.
Here’s what the interface to MPI_Sendrecv looks like:
https://www.mpich.org/static/docs/v3.0.x/www3/MPI_Sendrecv.html
Here’s the same example as above, but now using this single function.
#include <iostream>
#include <vector>
#include <mpi.h>
int main() {
MPI_Init(nullptr, nullptr);
std::vector<int> data(5, 0);
int mype{-1};
MPI_Comm_rank(MPI_COMM_WORLD, &mype);
int num_procs{0};
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
// fill the interior 3 data elements
data[1] = 3 * mype;
data[2] = 3 * mype + 1;
data[3] = 3 * mype + 2;
// send to the left and receive from the right
//
// send: mype -> mype - 1
// receive: mype <- mype + 1
int sendto{MPI_PROC_NULL};
int recvfrom{MPI_PROC_NULL};
if (mype > 0) {
sendto = mype-1;
}
if (mype < num_procs-1) {
recvfrom = mype+1;
}
MPI_Status status;
MPI_Sendrecv(&data[1], 1, MPI_INT, sendto, 0,
&data[4], 1, MPI_INT, recvfrom, 0,
MPI_COMM_WORLD, &status);
// send to the right and receive from the left
//
// send: mype -> mype+1
// receive: mype <- mype-1
sendto = MPI_PROC_NULL;
recvfrom = MPI_PROC_NULL;
if (mype < num_procs-1) {
sendto = mype+1;
}
if (mype > 0) {
recvfrom = mype-1;
}
MPI_Sendrecv(&data[3], 1, MPI_INT, sendto, 1,
&data[0], 1, MPI_INT, recvfrom, 1,
MPI_COMM_WORLD, &status);
std::cout << "PE: " << mype << " data: ";
for (auto e : data) {
std::cout << e << " ";
}
std::cout << std::endl;
MPI_Finalize();
}