
Second-order Advection#
To get a more accurate solution, we need to handle both the space and time discretizations in a higher order fashion.
First, let’s look again at the definition of the average:
let’s substitute in a Taylor expansion about \(x_i\):
inserting this into our integral, we have:
Look at the terms:
the first term is just a constant, so it’s integral is just \(a(x_i) \Delta x\)
the second term is odd over the interface \([x_{i-1/2},x_{i+1/2}]\), so it integrates to 0
the third term will integrate to something like \((\Delta x)^3\) (before we divide by the \(\Delta x\) out front)
This means that
So if we work to second-order in space, then we don’t need to worry about the difference between the cell average and cell-center.
Note
To make the notation easier, we’ll drop the \(\langle \rangle\) from now forward.
Temporal discretization#
There are 2 broad ways that we can handle the time integration to get more accuracy:
Predict our interface states at the midpoint in time using a Taylor expansion (in both space and time). This would result in a time-centered interface state. This procedure is sometimes called characteristic tracing.
Just construct high-order interface states in space, ignoring how they evolve in time, and use a high-order integrator (like Runge-Kutta) to handle the time integration. This is called the method-of-lines approach.
We’ll focus on the second approach (method-of-lines). For details on the first, see my notes: Computational Hydrodynamics for Astrophysics
Piecewise linear reconstruction#
For the first order method, we did the reconstruction to the interfaces by assuming that \(a(x)\) is constant in a cell. This is called piecewise constant reconstruction.
To be higher-order accurate, we need to allow for some variation in the zone. The next easiest approach is to allow \(a(x)\) to vary linearly in the zone. This is called piecewise linear reconstruction.
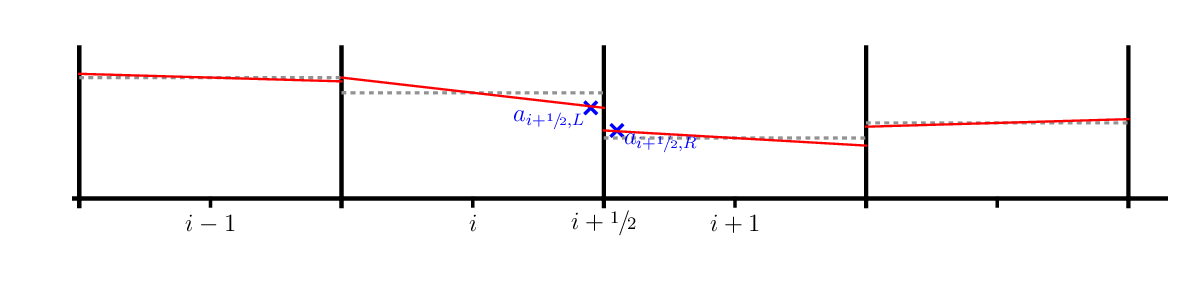
In the figure above, the cell-average is represented by the dotted gray line and the reconstructed slopes, \(\Delta a_i\), are the red solid lines. We can use a centered-difference for the slope, e.g.,
Our reconstructed form of \(a(x)\) in zone \(i\) in this case is:
and this is conservative, e.g.,
Then we construct the interface states by following this slope from the value \(a_i\) at \(x_i\) to the two interfaces for that zone. Note that zone \(i\) connects to the right state on the left interface (\(i-1/2\)) and the left state on the right interface (\(i+1/2\)):
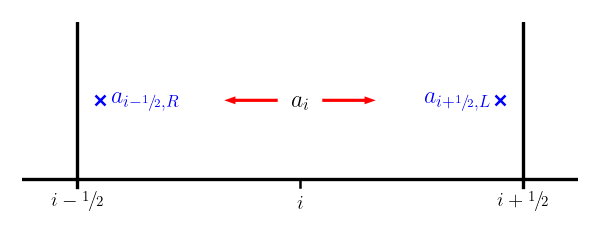
Therefore, we have:
There is one additional complication: we need the interface state just outside the physical domain, which means that we need to construct a slope there, which in turn means that we need to have an additional ghost cell to allow us to compute the centered-difference slope. So for this method, we need 2 ghost cells on each side.
Implementation#
We’ll continue to use the same FVGrid class
from fv_grid import FVGrid
import numpy as np
Now, we’ll use 2nd order Runge-Kutta. If we use the implementation ideas from before, then we want a RHS function that we can call that just gives us the update. Here we are thinking of our equation as:
where
def flux_update(gr, u, a):
"""compute -div{F} for linear advection"""
# slope
da = gr.scratch_array()
da[gr.ilo-1:gr.ihi+2] = 0.5*(a[gr.ilo:gr.ihi+3] - a[gr.ilo-2:gr.ihi+1])
# upwinding means that we take the left state always
# convection: aint[i] = a_{i-1/2}
aint = gr.scratch_array()
aint[gr.ilo:gr.ihi+2] = a[gr.ilo-1:gr.ihi+1] + 0.5*da[gr.ilo-1:gr.ihi+1]
flux_diff = gr.scratch_array()
flux_diff[gr.ilo:gr.ihi+1] = u * (aint[gr.ilo:gr.ihi+1] - aint[gr.ilo+1:gr.ihi+2]) / gr.dx
return flux_diff
Now we write the time update. This is going to look a lot what we did with orbits. The main thing we need to remember is that we need to fill the ghost cells before we compute the RHS
def advection_mol(nx, u, C, num_periods=1, init_cond=None):
# create a grid
g = FVGrid(nx, ng=2)
t_period = (g.xmax - g.xmin) / np.abs(u)
tmax = num_periods * t_period
# setup initial conditions
init_cond(g)
g.ainit[:] = g.a[:]
# compute the timestep
dt = C * g.dx / np.abs(u)
t = 0.0
while t < tmax:
if t + dt > tmax:
dt = tmax - t
# second-order RK integration
g.fill_BCs(g.a)
k1 = flux_update(g, u, g.a)
atmp = g.scratch_array()
atmp[:] = g.a[:] + 0.5 * dt * k1[:]
g.fill_BCs(atmp)
k2 = flux_update(g, u, atmp)
g.a[:] += dt * k2[:]
t += dt
return g
We’ll get the initial condition functions from our advection module
from advection import tophat, gaussian
C = 0.5
u = 1.0
nx = 128
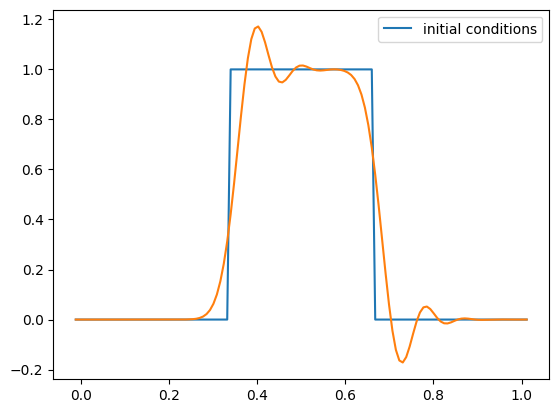
g = advection_mol(nx, u, C, init_cond=tophat)
fig = g.plot()
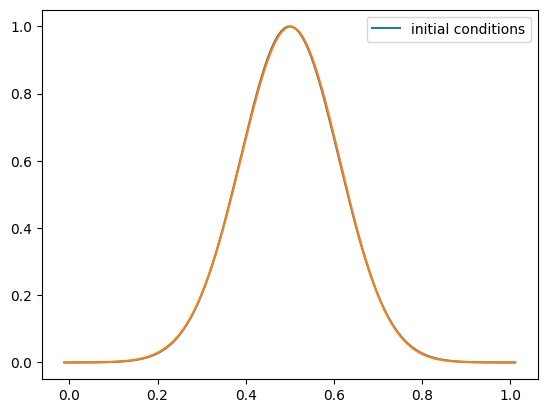
Now the Gaussian initial conditions
g = advection_mol(nx, u, C, init_cond=gaussian)
fig = g.plot()
Slope Limiters#
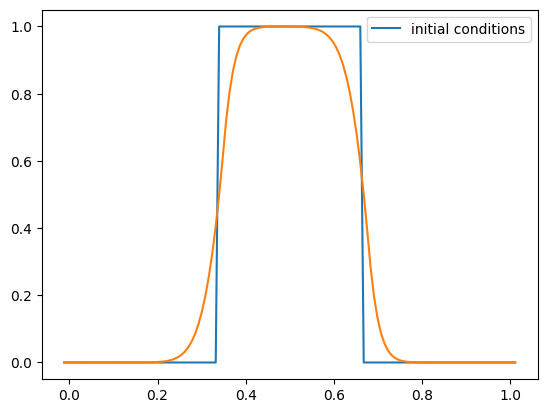
One thing you’ll notice is that with tophat initial conditions, there are oscillations near the discontinuities. We don’t see these with the smooth run.
Godunov’s theorem says:
Any monotonic linear method for advection is first order accurate
and the converse is true as well. This means that in order to be monotonic and second-order accurate, we need to make our method nonlinear.
This is accomplished through the use of slope limiters. A limiter modifies the piecewise linear slopes near extrema to prevent overshoots. Mathematically they enforce a property called total variation diminshing.
A simple limiter is the minmod limiter:
with:
Tip
Most limiters have a form like this. The key is the check \(a \cdot b > 0\). That is checking if the slopes on the left and right of the interface are the same sign. If they are not the same sign, then we are at an extrema (a minimum or maximum) and those are the situations where we want to limit.
Here’s a visualization of the effect of the limiter:
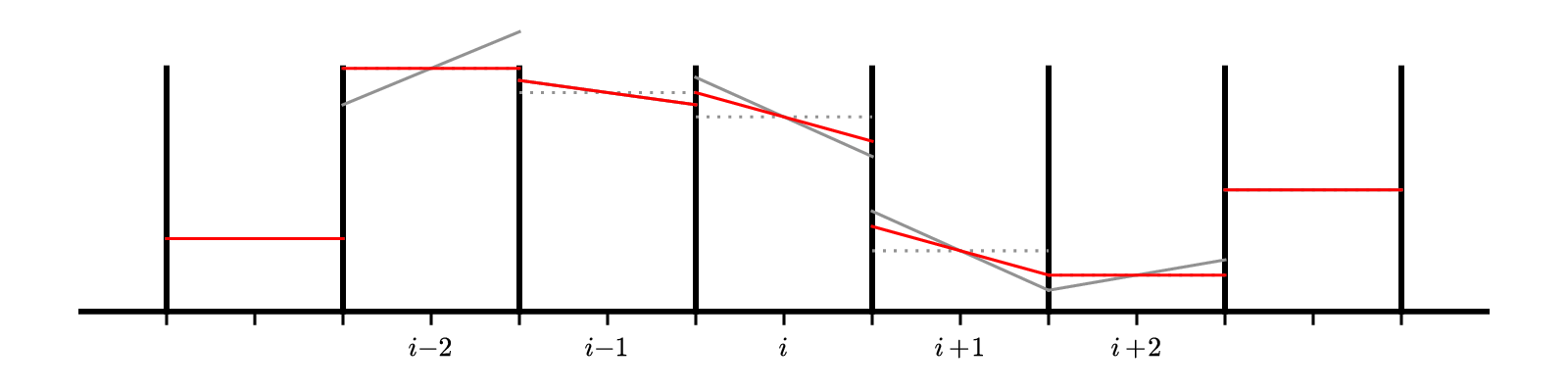
The gray lines are the original unlimited slopes. Notice that the slope at \(i - 2\) goes well above the original data on the right edge of the domain. That zone is a maximum. The limited slopes are shown in red. For zone \(i-2\) the result of the limiting is to completely flatten the profile—we go to piecewise constant in that zone.
Running with limiting#
We need to rewrite the flux function with our limiters. Once we run this cell, this will take precedence over the previous, unlimited version.
def flux_update(gr, u, a):
"""compute -div{F} for linear advection"""
# slope
# dl = a_i - a_{i-1}
dl = gr.scratch_array()
dl[gr.ilo-1:gr.ihi+2] = a[gr.ilo-1:gr.ihi+2] - a[gr.ilo-2:gr.ihi+1]
# dr = a_{i+1} - a_i
dr = gr.scratch_array()
dr[gr.ilo-1:gr.ihi+2] = a[gr.ilo:gr.ihi+3] - a[gr.ilo-1:gr.ihi+2]
d1 = np.where(np.fabs(dl) < np.fabs(dr), dl, dr)
da = np.where(dl*dr > 0.0, d1, 0.0)
# upwinding means that we take the left state always
# convection: aint[i] = a_{i-1/2}
aint = gr.scratch_array()
aint[gr.ilo:gr.ihi+2] = a[gr.ilo-1:gr.ihi+1] + 0.5*da[gr.ilo-1:gr.ihi+1]
flux_diff = gr.scratch_array()
flux_diff[gr.ilo:gr.ihi+1] = u * (aint[gr.ilo:gr.ihi+1] - aint[gr.ilo+1:gr.ihi+2]) / gr.dx
return flux_diff
C = 0.5
u = 1.0
nx = 128
g = advection_mol(nx, u, C, init_cond=tophat)
fig = g.plot()
Convergence#
u = 1.0
C = 0.5
for nx in [32, 64, 128, 256, 512]:
g = advection_mol(nx, u, C, init_cond=gaussian)
print(f"{nx:3d}: {g.norm(g.a - g.ainit):10.8f}")
32: 0.07860716
64: 0.03039718
128: 0.01176779
256: 0.00393815
512: 0.00123781
We see convergence that is better than first order accurate, but not second. The reason is due to the limiters. When the limiters act at an extrema, they zero out the slope, dropping the order (in space) to first-order accurate.
There are limiters that do a better job than minmod() that can be explored to help fix this.
Exercise
Rerun the convergence test, but use unlimited slopes