AMReX-Astrophysics
Castro: compressible flows
Our group develops the Castro compressible (magneto-, radiation) hydrodynamics code. Castro supports a general equation of state, arbitrary nuclear reaction network, full self gravity w/ isolated boundary conditions, thermal diffusion, flux-limited diffusion (multigroup) radiation, rotation, and more.
Castro runs on anything from laptops to supercomputers, using MPI+OpenMP for CPUs and MPI+CUDA for GPUs.
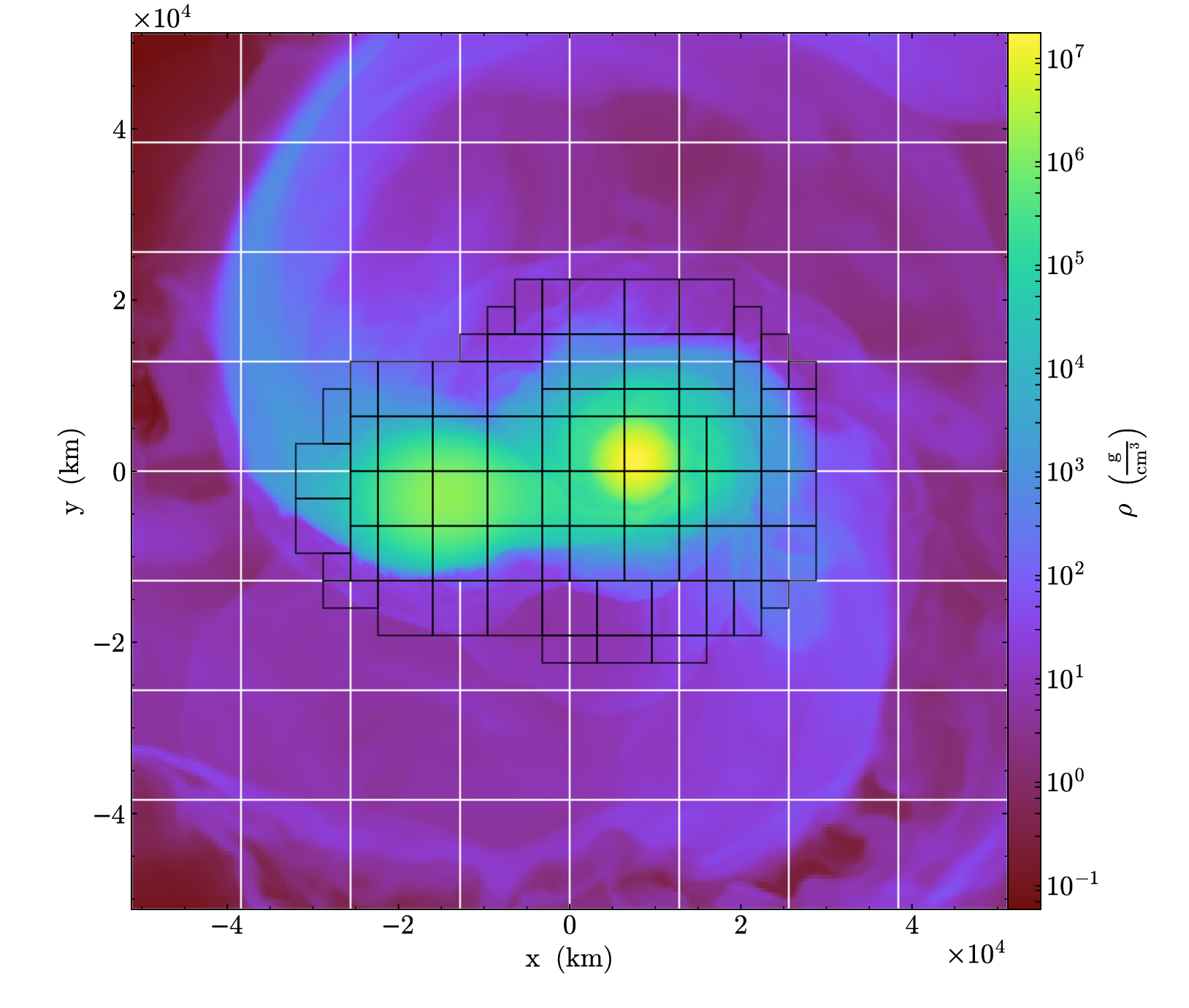
We use Castro for our white dwarf merger and X-ray burst simulations.
MAESTROeX: low Mach number stellar flows
We also develop (together with LBNL) the MAESTROeX low Mach number stellar hydrodynamics code. MAESTROeX filters soundwaves from the equations of hydrodynamics while keeping compressibility effects due to stratification and local heat release. This enables it to take large timesteps, not constrained by the soundspeed, for subsonic flows.
We use MAESTROeX (and its predecessor MAESTRO) for our white dwarf convection, X-ray burst, and sub-Chandra Type Ia supernovae simulations.
Reactive flows
All of our simulations involve reacting flows—the immense energy release from nuclear burning drives hydrodynamic flows. These two processes need to be tightly coupled together to ensure that we accurately capture the dynamics and nucleosynthesis. The traditional method of coupling hydrodynamics and reactions in astrophysics has been Strang splitting, a type of operator splitting where the reactions and hydrodynamics operations each act on the state left behind from the other process, but there is no explicit coupling. We have been developing spectral deferred correction (SDC) techniques to strongly couple the two processes. In SDC methods, the hydrodynamics explicitly sees a reaction source and the reactions take into account how advection alters the state during the burn. Iteration is used to fully couple the processes. SDC methods are integrated into both Castro and MAESTROeX.
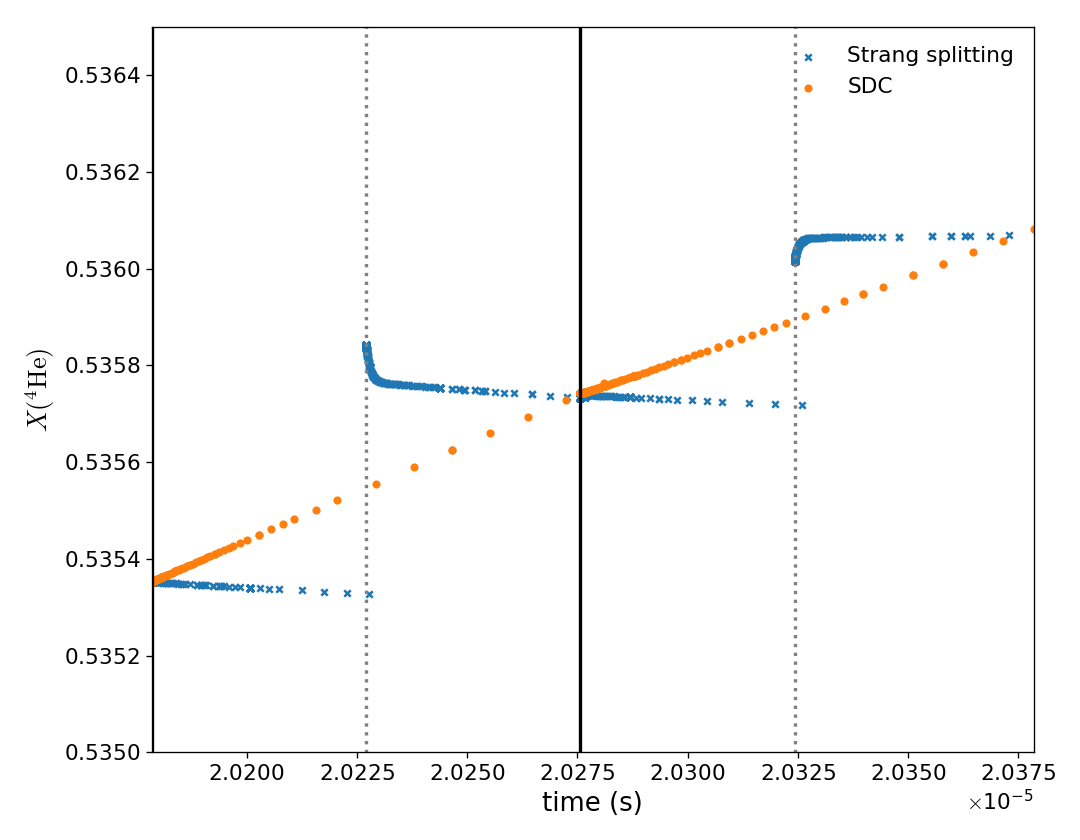
Two timesteps from a Castro detonation calculation, showing the helium mass fraction. The orange points show the state in the SDC evolution where each point represents substep used in integrating the reaction network. By coupling the advection directly to the reaction evolution, we see the evolution is smooth an continuous. In the Strang case, we see the reactions in the first Δt/2 of the evolution take the state far from the smooth SDC solution. Advection at the midpoint in time over-corrects the solution, and then the final Δt/2 of reaction brings us back to the SDC solution.
Performance portability
All of our codes are written to be performance portable%mdash;able to run on anything from a laptop to a supercomputer. Through the AMReX library, we write our compute kernels in C++ and use Parallel-For loops that loop over the zones in a grid. On GPUs, each zone is assigned to a GPU thread, while on CPUs, we use logical tiling and OpenMP to distribute the work over processor codes.
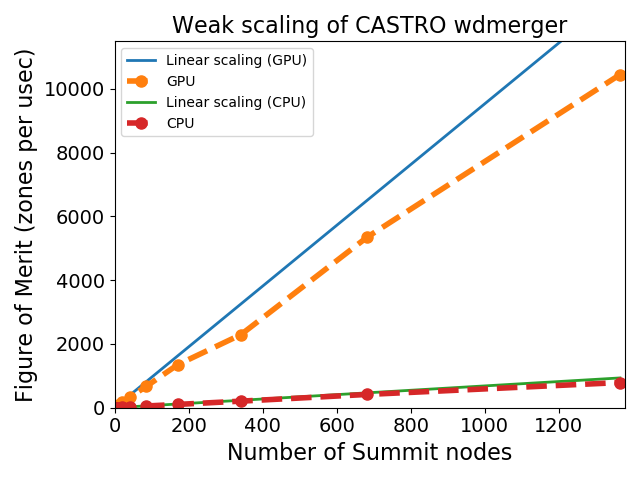
Comparison of GPU (6 NVIDIA V100 / node) and CPU (42 Power9 cores / node) on the OLCF Summit machine for a merge white dwarf simulation (hydrodynamics and full self-gravity).