This page attempts to discuss how to take data from a parallel hydrodynamics code and store it in a single file on disk. We choose to use the HDF5 format for this tutorial.
Two methods are presented here: serial and parallel I/O. The ultimate goal is to have a single file containing our data from all the processors. The parallel I/O method is preferred (and much simpler to code), but requires that the machine have a parallel file system (i.e. GPFS, PVFS) for best performance. NFS mounted disks probably may not perform too well (see the MPICH bugs page).
The HDF5 library provides a set of high level library functions for describing and storing simple and complex data structures. The library automatically stores datatype information and metadata describing the rank, dimensions, and other data properties. Conversion functions between datatypes are also provided, and the data is stored portably, so no byte swapping is necessary when reading the data in on a platform with a different endianness.
Data is stored in datasets, which can be queried to find out the size, layout, etc. Data can be read by specifying the name of the dataset (like 'density'), instead of having to know the details of how the file is laid out. This allows anyone to be able to query and read in the data without having to know the details of how it was written out.
Finally, HDF5 allows for parallel I/O (through MPI-IO), while maintaining the flexibility of the file format. Data written out in parallel can be read in serially on another platform without any conversion.
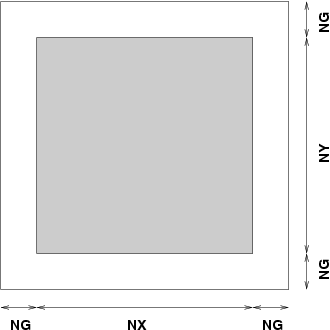
It is assumed that the hydro code carries around a (set of) data structure(s) that are basically an array with a perimeter of guardcells. This arrangement is very common in hydrodynamics -- the guardcells serve to hold the data from off processor, or to implement the boundary conditions.
Each processor contains a data array with NX zones in the x-direction, and NY zones in the y-direction., and NG guardcells.
A further simpliciation is that the domain decomposition is in one-dimension only (we choose x). The total number of zones comprising the computational domain is NPES*NX x NY. This is illustrated below:
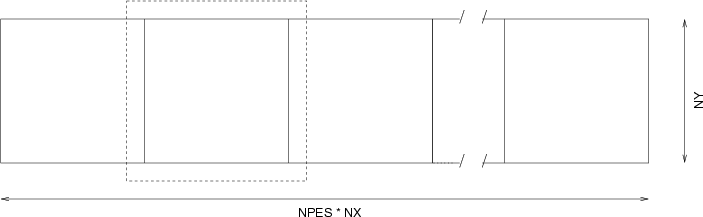
The dashed line indicates that actual extend of the 2nd processor's sub-domain -- showing the perimeter of guardcells.
We want to write the data out into a single file, and organize it like it as pictured above. The benefit to this arrangemnent (as compared to storing each proc's data in a separate array), is that it is then relatively easy to restart on a different number of processors. The computational domain can be cut into a different number of pieces upon restart, and those chucks can just be read from the since record in the file.
The first example serves to familiarize the user with the HDF5 library and how to select only a portion of an array for storage -- in our case, the interior zones.
HDF5 uses the concept of dataspaces and memory spaces to deal with the passing data from memory to file. The memory space describes the layout of the data to be written as it exists in memory. The memory space does not need to be contiguous.
The dataspace describes the layout of the data as it will be stored in the file. As with the memory space, there is no constraint that the elements in the dataspace be contiguous.
When data is written (via the H5Dwrite call), the data is transferred from memory to disk. It is required that the number of elements in the memory space be the same as that in the dataspace -- the layouts do not need to match however. If the data is non-contiguous, a gather/scatter is performed during the write operation.
The first example defines a dataspace in the HDF5 file large enough to hold the interior elements of one of our patches. A memory space is created describing the array, and the interior cells are picked out using a hyperslab select call.
The source code implementing this procedure is here: hdf5_simple.c
One way to get the data from multiple processors into a single file on disk is to explicitly send it all to one processor, and have only that master processor open the file, do the writing, and close the file. The code this more complicated than the parallel I/O version we look at below, but on some systems (i.e. those lacking a parallel filesystem), it may be the only option.
We assume that each processors has one or more data arrays declared
as
double data[2*NG+NY][2*NG+NX]
Alternately, there could be a single data array with an
extra dimension to hold the different variables carried by the hydro
code
double data[2*NG+NY][2*NG+NV][NVAR]
In the example below, we assume a single variable. Adding multiple
variables simply requires an extra loop over the number of variables
wrapping the code shown below.
In addition to the data array(s), we need a single buffer array
that will just hold the interior zones (i.e. excluding the guardcells)
from the data array for the current variable. This array is just of
size NX x NY
double buffer[NY][NX]
Furthermore, it is important that the elements in these arrays be contiguous
in memory. In Fortran, declaring a multidimensional array as:
real (kind = dp), dimension (NX, NY) :: buffer
guarantees that the elements are contiguous. In C, it is necessary to
allocate a 1-d array of size NX*NY to guarantee that the elements are
contiguous (see the examples).
The basic algorithm for writing the data is to designate one processor as the master processor -- this is the processor that will open the file, do the writing, and then close the file. All other processors will need to send their data to the buffer array on the master processor in order for it to be written out. We assume that the master processor is processor 0.
To start, each processor (including the master processor) copies the interior cells from the data array into the buffer array on they've allocated. Then, a loop over all processors is performed, and the data is written out in processor order. The first processor to write out its data is processor 0 (our master processor). It already contains the data it needs in its buffer array, so it simple writes its data to the file.
When writing to the HDF file, we need to create a dataspace in the file. This describes how the data will be stored in the file. We tell the library that our dataspace is NPES*NX x NY cells. Each processor only writes to a subset of that dataspace, and we need to tell the HDF5 library which subset to write to before the actual write. This is accomplished via the hyperslab function in the HDF5 library. We give it a starting point, a size, and a stride, and it knows which portion of the dataspace to write to.
After processor 0's data is written, we move to the next processor. Now we need to move the data from the buffer on processor 1 to the buffer on processor 0. This is accomplished by an MPI_Send/Recv pair. Once the data is sent, processor 0 can write it's buffer (no holding processor 1's data) to the file. This process is outlined in the figure below.
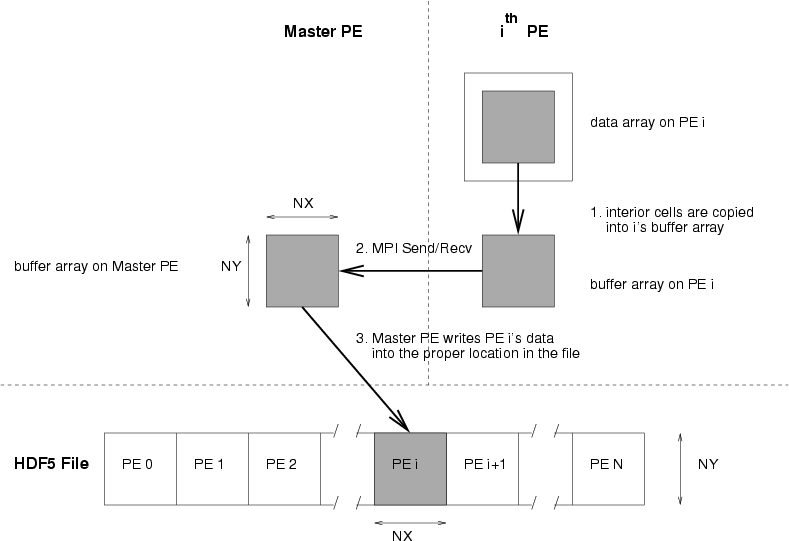
The source code implementing this procedure is here: hdf5_serial.c, Makefile
A better way to get the data from multiple processors into a single file on disk is to rely on the underlying MPI-IO layer of HDF5 to perform the necessary communication. MPI-IO implementations on different systems are usually optimized for their platform and can perform quite well.
As above, we assume that each processors has one or more data arrays
declared as
double data[2*NG+NY][2*NG+NX]
In contrast to the serial example, we do not require a buffer array, rather, we rely of the HDF5 hyperslab functionality to pick out only the interior of our array when writing to disk. Each processor opens the file (in parallel), creates the dataspaces and memoryspaces, and writes the data directly to the file. There is no explicit communication here.
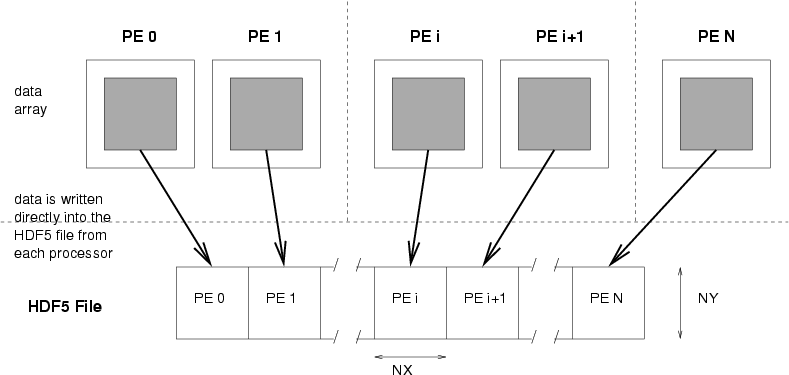
The source code implementing this procedure is here: hdf5_parallel.c
In addition to performing the I/O, an MPI_Info object is created and passed to the MPI-IO implementation through the HDF5 library. This object contains hints, described in the MPI-2 I/O chapter. These hints should be experimented with in order to find the best performance.
May, J. M., "Parallel I/O for High Performance Computing", Morgan Kaufmann Publishers, 2001.
Ross, R., Nurmi, D., Cheng, A., and Zingale, M., "A Case Study in Application I/O on Linux Clusters", 2001, [PDF] (from sc2001.org)